Kanonizace vám ve většině případů pomůže vyřešit problémy s duplicitami na webu nebo e‑shopu. Duplicitní obsah může vzniknout kopírováním obsahu z jiných zdrojů (konkurence, dodavatel, výrobce) a taky kvůli špatným technickým vlastnostem. S využitím kanonizace můžete problém duplicitního obsahu vyřešit, vyhledávače budou spokojené a nedojde ke zhoršení SEO výkonu.
Co to je kanonická URL a k čemu slouží?
Kanonizace (rel=“canonical”) je HTML prvek pomáhající předcházet problémům s duplicitním obsahem. Vložením prvku canonical upřednostníte jednu stránky před ostatními stránkami se stejným, nebo velmi podobným obsahem na více URL adresách.
Kanonická URL slouží jen jako doporučení pro vyhledávače, nicméně je považována za hodnotící faktor a víme, že ji vyhledávače používají.
Nejčastěji se pomocí kanonizace řeší:
- varianty produktů,
- duplicitní kategorie,
- štítky na blogu,
- a parametry v URL adresách.
Pokud budete mít produkt, který existuje ve více variantách (barva, velikost, objem apod.), a neoznačíte hlavní variantu atributem rel=”canonical”, vzniknou z ostatních variant duplicity.
Jak vypadá a kde se nejčastěji vyskytuje kanonická URL
Kanonická URL adresa (rel= “canonical”) se nejčastěji nachází v HTML hlavičce head.
Chcete se přesvědčit, jestli v HTML kódu tento prvek máte? Stačí se do kódu podívat. Stisknete pravé tlačítko myši, zvolíte zobrazit zdrojový kód stránky, nebo prozkoumat prvek, a v hlavičce head byste měli najít canonical (Obr. 1).
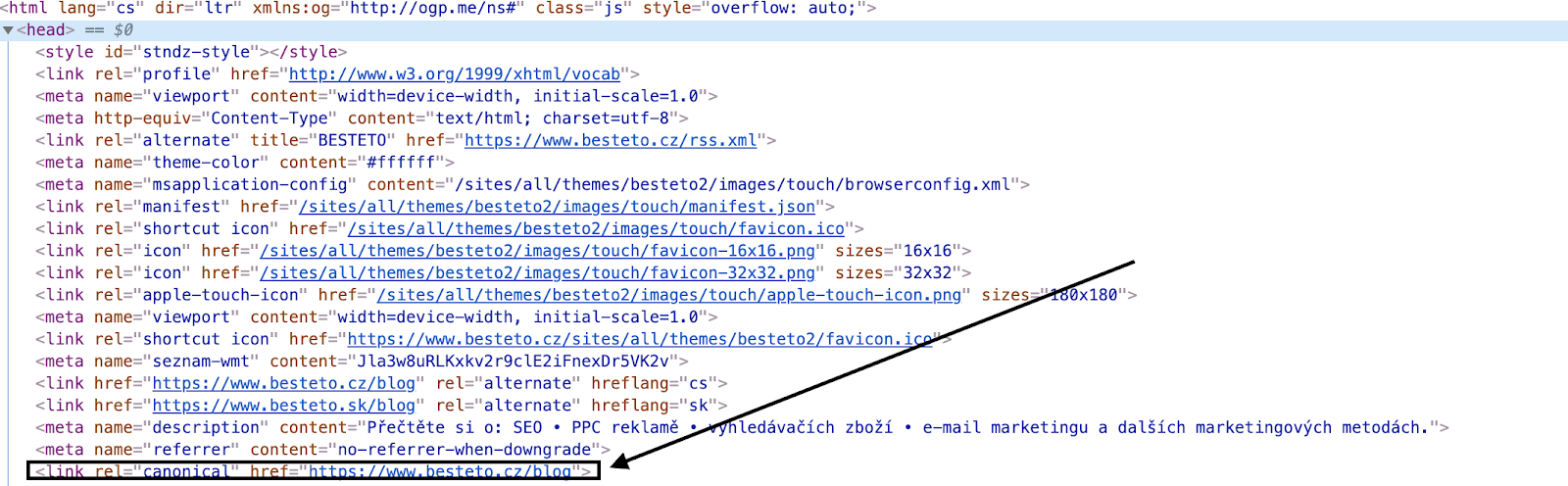
Jak nastavit HTML tag ( rel=”canonical”)
Řekněme že máme jeden produkt, který má více barevných provedení (červená, zelená, bílá, modrá, žlutá).
Takto vypadají URL adresy jednotlivých barevných variant:
https://www.priklad.cz/produkt/tenisova-raketa-head-cervenahttps://www.priklad.cz/produkt/tenisova-raketa-head-zelenahttps://www.priklad.cz/produkt/tenisova-raketa-head-bilahttps://www.priklad.cz/produkt/tenisova-raketa-head-modrahttps://www.priklad.cz/produkt/tenisova-raketa-head-zluta
Pokud bychom nedosadili kanonickou URL, vytvořili bychom 5 duplicit.
Zvolíme jednu variantu jako hlavní stránku (např. raketu bílou), kterou chceme zaindexovat, a která bude mít v hlavičce head nastavenou kanonickou URL sama na sebe:
<head>
<link rel = “canonical” href=”https://www.priklad.cz/produkt/tenisova-raketa-head-bila” />
</head>
Jakmile máme definovanou hlavní URL adresu, kterou chceme indexovat, označíme ostatní adresy:
- Červená raketa
<link rel = “canonical” href=”https://www.priklad.cz/produkt/tenisova-raketa-head-bila” />
- Zelená raketa
<link rel = “canonical” href=”https://www.priklad.cz/produkt/tenisova-raketa-head-bila” />
- Modrá raketa
<link rel = “canonical” href=”https://www.priklad.cz/produkt/tenisova-raketa-head-bila” />
- Žlutá raketa
<link rel = “canonical” href=”https://www.priklad.cz/produkt/tenisova-raketa-head-bila” />
Správné použití tagu canonical
Kanonická URL by vždy měla odkazovat na indexovatelnou stránku. V některých případech se stává, že adresa odkazuje na stránku pomocí přesměrování 301, což může vyhledávače zmást. V souboru sitemap.xml (seznam všech stránek na webu) by měla být pouze jedna indexovatelná (hlavní) stránka dané verze — viz výše uvedený příklad s tenisovou raketou.
Kanonickou URL můžeme použít dvěma způsoby:
Odkazující sama na sebe (self-canonical)
Používá se, pokud máte na e‑shopu možnost řazení (např. seřadit zboží podle ceny, názvu,…) a vzniká velké množství URL adres.
Zde je příklad, jak by po seřazení zboží URL adresy mohly vypadat:
https://www.priklad.cz/produkt123
https://www.priklad.cz/produkt123?sort=brand (řazení podle značky)
https://www.priklad.cz/produkt123?sort=price (řazení podle ceny)
https://www.priklad.cz/produkt123?sort=size (řazení podle velikosti)
https://www.priklad.cz/produkt123?sort=size&brand (kombinace řazení)
https://www.priklad.cz/produkt123?sort=size&brand&price
V tomto případě kanonická URL zabrání, aby se tyto adresy indexovaly a sdělí vyhledávačům, že existuje pouze jedna verze této stránky.
Parametry se mohou do URL dostat i jinak. Příkladem je uživatel, který se na váš článek proklikne z PPC reklamy nebo mailingu. U těchto URL adres vkládáme pro sledování návštěvnosti trackovací (UTM) parametry. Samy o sobě UTM parametry nejsou problém. Pokud ale takový uživatel zkopíruje URL adresu i s parametry a vloží ji jako odkaz někde jinde místo toho, aby použil původní URL adresu článku, najdenou tu máme divnou URL dohledatelnou vyhledávačem.
Doporučujeme implementovat self-canonical vždy, pokud to situace umožňuje.
Odkazující na jinou stránku
Používá se v případě, že existuje více verzí jedné stránky. Při nastavení kanonizace byste měli používat absolutní URL adresu, aby vyhledávačům bylo jasné, že přesně tato adresa má být indexována.
Co je absolutní a relativní adresa?
- U absolutní adresy nelze zpochybnit, kam odkazuje a vypadá takto:
<link rel=”canonical” href=”https://www.besteto.cz/seo/blog/”>
- Relativní URL adresa vypadá nějak takto: <link rel=”canonical” href=”
seo/blog”>
Zde není příliš jasné o jaké umístění se jedná. Canonical se používá i mezi doménami, tudíž můžeme odkazovat na různé domény, nejen na tu naší. Proto je dobré použít absolutní adresu, aby bylo jasné, že canonical vede na nějakou stránku v rámci naši domény.
Další možnosti, kde kanonickou URL nastavit
Máme několik možností jak nastavit kanonickou URL adresu.
- HTML tag (rel= “canonical”): Tento způsob právě popisujeme. :)
- HTTP hlavička: Zejména se používá pro dokumenty jako PDF. Důvod proč se tato metoda uplatňuje u dokumentů je ta, že PDF soubor jako takový není samotná stránka. Tuto metodu podporuje pouze Google a jen pro výsledky vyhledávání na webu.
- Sitemap.xml: V sitemap.xml by se měli vyskytovat pouze stránky, které jsou hlavní. To znamená stránky, u kterých chceme, aby s nimi pracovaly vyhledávače a duplicitní stránky na ně odkazuji pomocí canonicalu.
- Přesměrování 301: Sjednocení zbytečných stránek vyřešíte pomocí trvalého přesměrování 301. Využijete ho, pokud je stránka dostupná jak přes HTTP protokol, tak přes HTTPS. Dále pokud je stránka dostupná na více doménách, které nemají žádný účel. Doporučujeme vytvořit kanonickou URL adresu i pro přesměrované URL adresy.
Nejčastější chyby
I tady se dá vymyslet spousta chyb. Když o nich budete vědět, určitě se jim vyhnete obloukem.
- Nastavení kanonické URL s atributem noindex
Nikdy byste neměli používat zároveň kanonickou adresu a atribut noindex, protože jsou to opačné příkazy. Atributem noindex říkáte vyhledávačům, aby danou stránku neindexovaly a zárověn kanonickou adresou jim sdělujete, by tuto adresu indexovaly.
- Kanonické adresy směřují na úvodní stránku kategorie při použití atributů rel=“next” a rel=“next”
Stránkování pomocí atributů rel=“next” a rel=“next“je metoda, která se používá například pro rozdělení produktových nebo blogových stránek kategorií na více částí. Je to z důvodu toho, aby vyhledávače věděli, že obsah je rozdělen do více části a nevytvářeli zbytečně duplicitní obsah. Google tvrdí, že tuto metodu už delší dobu nepodporuje. Nicméně mu trochu nevěříme a stále ji doporučujeme.
- Kanonická url obsažena v HTML elementu <body></body>
Pokud umístíte značku rel= “canonical” do elementu body, vyhledávače ji budou ignorovat.
- Řetězec kanonický adres
Pokud má stránka A nastavený rel=”canonical” na stránku B a stránka B má nastavený rel=”canonical” na stránku C. A → B → C. Takový řetězec může zmást vyhledávače a následně mohou usoudit, že takové řetězení budou ignorovat.
Teď už víte, jak se poprat s nežádoucími duplicitami. Aby vaše znalosti v oblasti duplicitního obsahu byly kompletní, brzy a blogu vydáme i článek čistě na toto téma. Jestli se bojíte, že o novinky na blogu přijdete, přihlašte se k odběru newsletteru.
Máte obavy z toho, že máte duplicity na webu? V rámci SEO auditu vám je rádi zkontrolujeme. Napište nám.
Komentáře (2)
Dobrý den paní Zajíčková,
jestliže se stránky liší pouze nepatrně, tak jsou označovány jako “blízké duplikáty”.
Pokud v tomto případě změníme hmotnost, tak se URL adresa a Title změní také, nicméně většina obsahu zůstane stejná.
Nabízí se 2 možnosti, jak tento problém vyřešit.
Uvedu na příkladu jak nastavit kanonickou URL.
Vyberete si jednu z adres, kterou chcete mít jako hlavní, například
https://oxalis.cz/cs/honeybush-1-kg-8594045068573 – 1668.htm/ a do hlavičky head v html kódu zadáte (self-canonical):
<link rel = “canonical” = https://oxalis.cz/cs/honeybush-1-kg-8594045068573 – 1668.htm/
Do zbývající adresy vložíte do hlavičky head v HTML kódu:
<link rel = “canonical” href= https://oxalis.cz/cs/honeybush-1-kg-8594045068573 – 1668.htm/
Snad Vám to takto pomůže.
S přáním hezkého dne,
Tomáš Gregorovič
Hezký den přeji,
skvělý článek! Chci se zeptat, když je na webu produkt, který se liší pouze hmotností, titulek se propisuje z názvu produktu, takže je odlišný, je to také bráno jako duplicita a je potřeba kanonizace? Viz https://oxalis.cz/cs/honeybush-60-g-8595218031967 – 1669.htm/ vs https://oxalis.cz/cs/honeybush-1-kg-8594045068573 – 1668.htm/ V Google Search Consoli vypadají, že jsou obě stránky v pořádku. Čekala jsem, že u jedné stránky bude, že je jedna stránka vyloučena kvůli tomu, že se jedná o duplicitní obsah.
S pozdravem
Nikol Zajíčková