Máte super stránku se spoustou skvělých informací a e‑shop plný exkluzivních produktů, ale Google ani Seznam o ní neví? Potom se o ní určitě nedozví ani potenciální návštěvníci. Jak to změnit? V návodu se dozvíte, jak zkontrolovat indexovanost vašeho webu a jak pomoci tomu, aby byla komplexnější a rychlejší.
Právě vstupujete do zóny plné informací pro SEO fanoušky. Tento návod vás provede tématem, ale obsahuje i rozšiřující informace a technické detaily.
Hledáte něco konkrétního? Použijte rozcestník.
Vyhledávače díky indexaci zobrazí ve výsledcích větší počet stránek vašeho webu a aktualizace nových nebo již existujících stránek dříve zaznamenají. Na konci článku vás za odměnu čeká i bonusový tip na získání náskoku před e‑shopy se stejným sortimentem.

Abyste vůbec zjistili, jak jsou na tom s indexací stránky vašeho webu, potřebujete vědět:
- celkový počet stránek vašeho webu,
- počet stránek vašeho webu, které už jsou zaindexované.
Seznam stránek webu najdete v souboru sitemap, což je skutečně taková “mapa” vašeho webu. URL adresu tohoto souboru byste měli najít v souboru robots.txt. Ten by se měl nacházet na adrese vasedomena.cz/robots.txt.
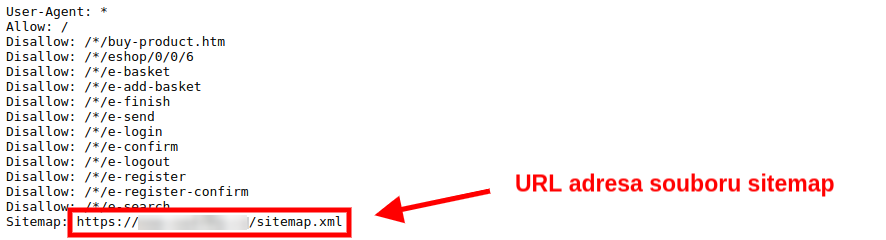
Ne vždy je v robots.txt adresa na sitemap. Pokud adresu nenajdete v souboru robots.txt můžete zkusit štěstí s nejčastějšími URL adresami sitemapy:
- vasedomena.cz/sitemap.xml
- vasedomena.cz/sitemap-index.xml
- vasedomena.cz/sitemap_index.xml
Jakmile máte adresu souboru sitemap, případně sitemap indexu, tak máte téměř vyhráno. Adresy otevřete přímo v prohlížeči a vyhledejte v nich prvky, kterými je uvedena každá URL adresa. Nástroj vyhledávání (klávesová zkratka CTRL+F) vám je pomůže i spočítat. Pro zjištění počtu URL adres obvykle funguje vyhledání výrazu “<url>”, což je název prvku a píše se včetně špičatých závorek.
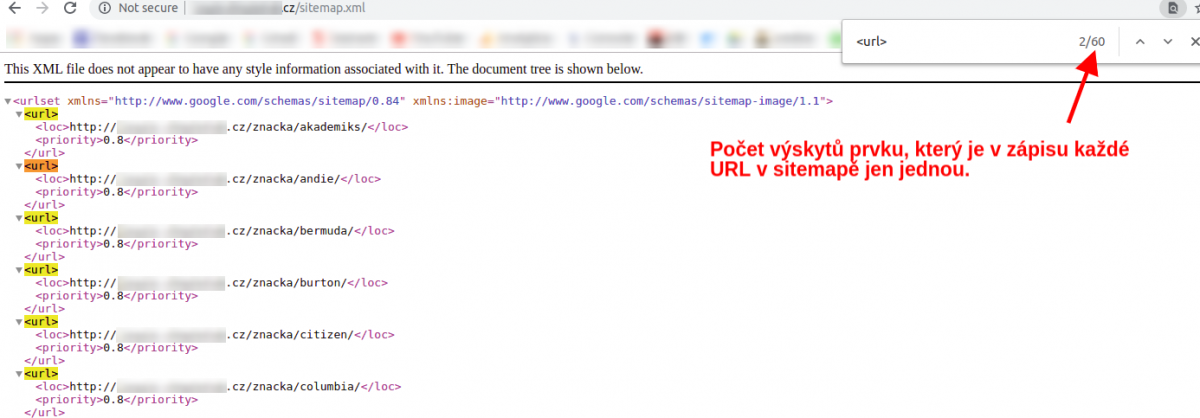
Sitemap index je rozcestník dílčích sitemap. V případě, že máte k dispozici právě tento soubor, ne jen jednu prostou sitemapu, musíte sečíst počet stránek ve všech dílčích sitemapách.
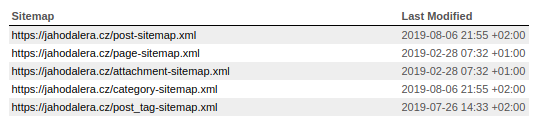
Tento rozcestník se používá třeba tehdy, když chce mít webmaster speciální sitemapu například pro stejné druhy stránek. Aby i pak byly dílčí sitemapy dohledatelné, vytvoří se k nim sitemap index. Na něj pak vede odkaz ze souboru robots.txt, z nástroje Google Search Console a jiných.
Více informací o souborech sitemap poskytuje nápověda Googlu a nápověda Seznamu.
Rozdělování sitemap má i další důležité využití. Pomůže vám udržet na uzdě například počet URL adres v rámci jednoho souboru sitemap. Existují totiž limity, které když překročíte, vyhledávače sitemapu už nezpracují.
U menších a středních e‑shopů je překročení limitů pro zpracování souboru sitemap.xml velmi neobvyklé. Pokud k němu dojde, tak obvykle vzniká problém právě s maximálním počtem URL adres, které v mohou být v jedné sitemapě.

Pokud máte URL adres v souboru sitemap více, je potřeba jej rozdělit na dílčí soubory, z nichž každý bude obsahovat maximálně 50 000 URL adres. A také musíte vytvořit výše zmíněný rozcestník v podobě sitemap indexu, který odkazuje na dílčí sitemapy.
Možná jste narazili na problém, protože vaše sitemapa není kompletní a vy se na takový výsledek sčítání nemůžete spolehnout. Sitemapa také nemusí vůbec existovat nebo obsahuje nesmysly.

Reálný počet stránek webu pak potřebujete zjistit jinak. V tom vám mohou pomoci crawlery. Jsou to nástroje, které procházejí web podobně jako roboti vyhledávačů. Nabídnete jim nějakou stránku webu a robot či crawler poté prochází všechny odkazy na každé stránce, na kterou se dostane. Tím se snaží vytvořit seznam všech stránek takto zkoumaného webu.
Crawler by měl odhalit všechny URL adresy webu, nejen stránky, ale i obrázky, css styly a další. Musí ale splňovat předpoklad, že na ně vede alespoň jeden odkaz z jiné stránky webu.
Mezi známé crawlery patří Screaming Frog a Xenu.
Nyní máte představu, kolik stránek má váš web. U menších a středně velkých e‑shopů to mohou být stovky až desetitisíce. Teď si ukážeme, jak ověřit kolik z nich je indexováno. Existují orientační nepřesná určení pomocí nástrojů zdarma a přesnější pomocí placených nástrojů.
Do vyhledávacího řádku můžete napsat operátor “site:”, který bude vyhledávat jen na konkrétním webu.
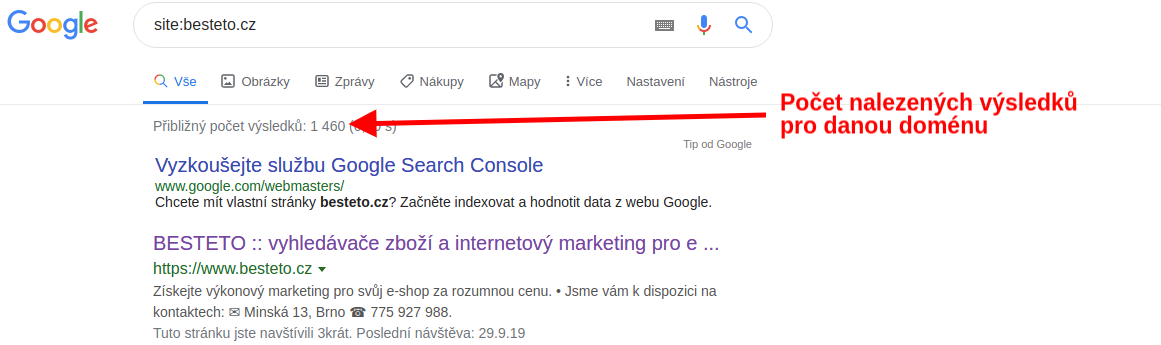
Pokud do vyhledávání zadáte “site:vasedomena.cz”, měly by se vám teoreticky objevit všechny Googlem indexované podstránky zkoumaného webu. Počet výsledků však může být hodně nepřesný. Tuto metodu tedy používejte opravdu jen pro váš přehled.
Pro orientační zjištění počtu nezaindexovaných stránek stačí odečíst počet výsledků vyhledávání od počtu stránek v sitemap.

Případně můžete zjistit poměr zaindexovaných stránek vydělením počtu výsledků vyhledávání počtem stránek v sitemapě.

Úplně stejně můžete použít vyhledávací operátor “site:” i ve vyhledávači Seznam. Jen hledání počtu výsledků je v něm složitější. Seznam od roku 2017 neukazuje počet výsledků ve vyhledávání v běžném zobrazení SERPu (stránky výsledků vyhledávání). Počet výsledků je ale stále vidět na stránce ve formátu RSS. Podrobný postup na to, jak získat počet výsledků vyhledávání na Seznamu, popisuje návod na Collabimu.
Ve zkratce: Stačí upravit URL adresu, která se objeví po načtení výsledků vyhledávání tak, aby za znakem &, který je v URL adrese po hledaném výrazu, byl text “format=rss”.
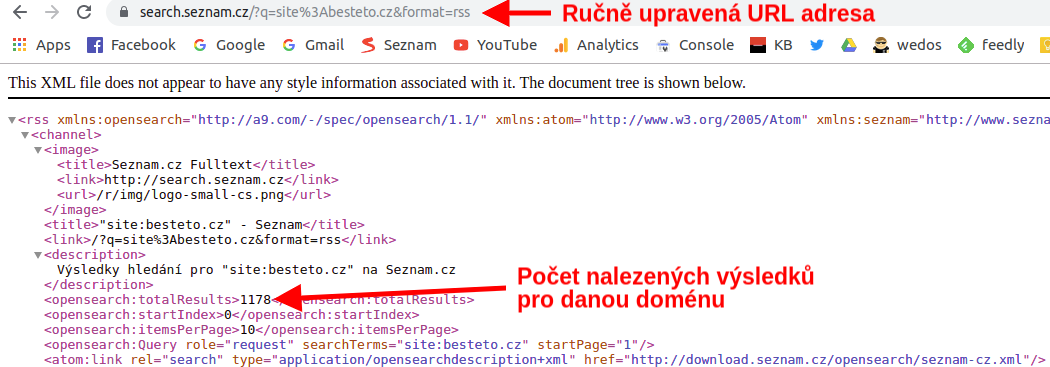
Pro podstatně přesnější zjištění počtu zaindexovaných stránek můžete využít placené nástroje, jako je Marketing Miner. Ten dokáže určit nejen, které stránky jsou indexované, ale i jestli jsou indexovatelné, tedy zda nějaký technický problém nebrání vyhledávačům v indexaci.
Výstupem je grafický přehled stavu, navíc také tabulka se stavem indexovanosti a indexovatelnosti pro každou podstránku, kterou jste v reportu vložili k prověření. Odhalíte tak, jestli jsou mezi neindexovanými stránkami důležité stránky (třeba kategorie produktů), které chcete mít zobrazené ve výsledcích vyhledávání.
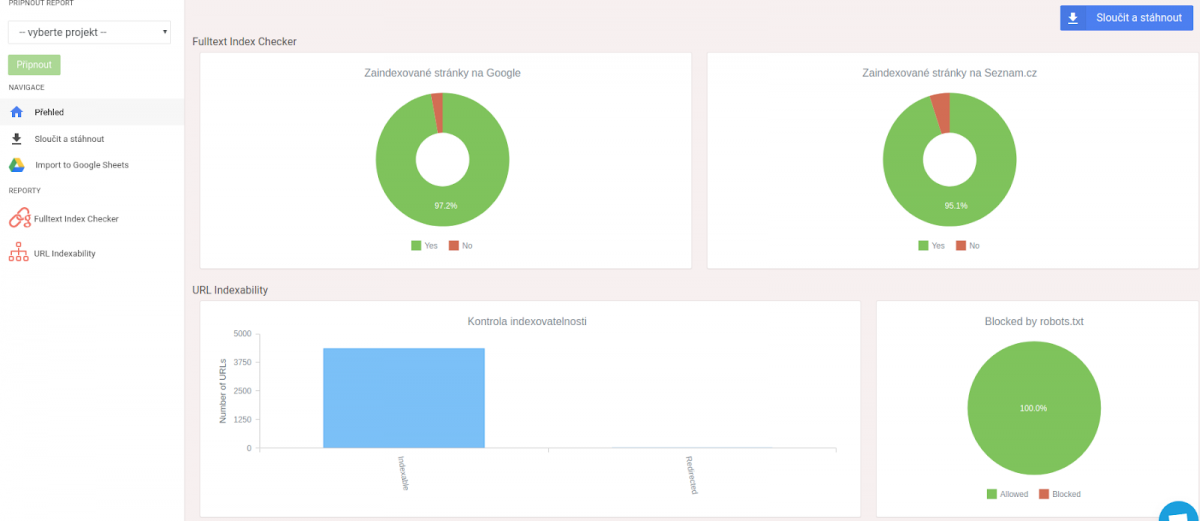
Postup kontroly indexovanosti popisuje nápověda Marketing Mineru.
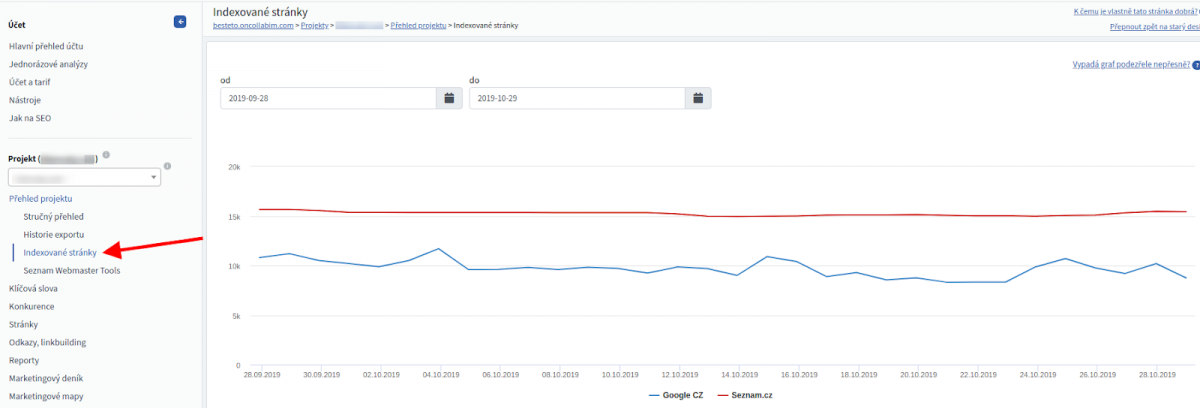
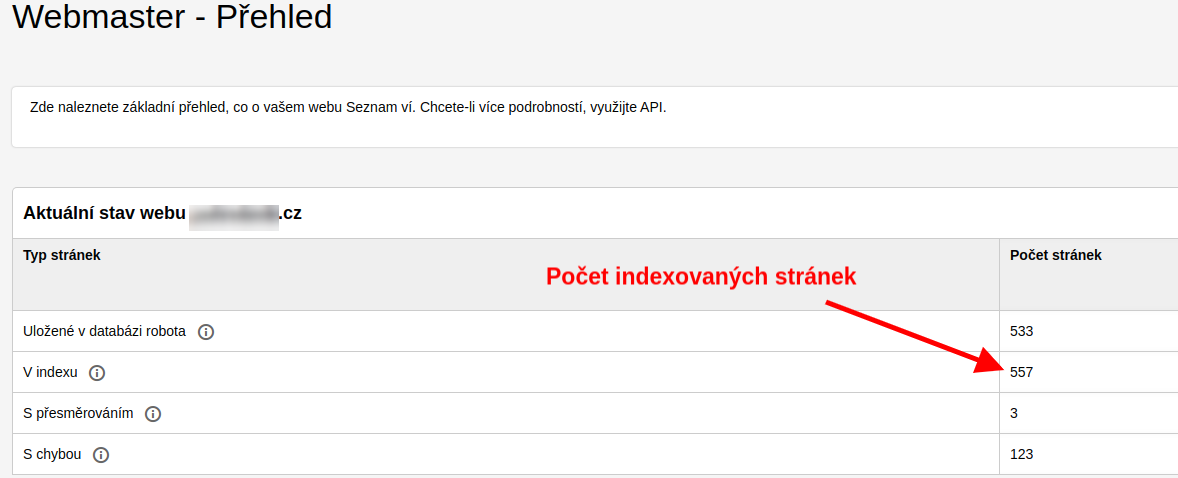
Pokud využíváte nástroj Collabim, můžete zjistit stav indexace jednorázovou analýzou URL adres. V již založeném projektu pro vaši webovou stránku můžete využít přehled vývoje indexace na Googlu i Seznamu v sekci Přehled projektu -> Indexované stránky.
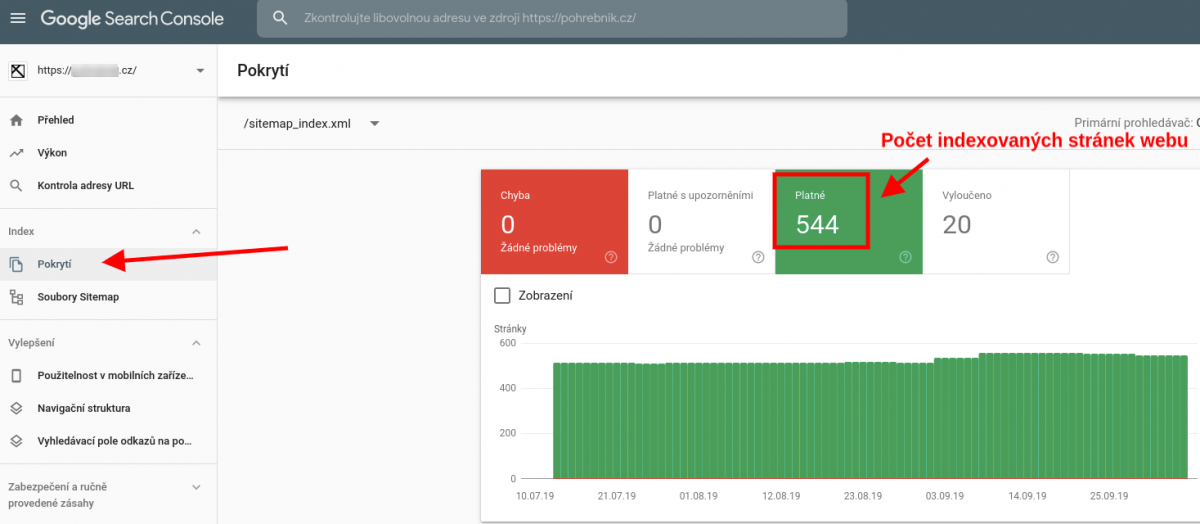
Bezplatné a přesné zjištění počtu indexovaných stránek vám poskytne nástroj Google Search Console. Stačí, že v něm máte svůj web registrovaný. Na přehledu “Pokrytí” si můžete zobrazit počet zaindexovaných stránek i s grafem vývoje indexace v průběhu času.
Obdobou Google Search Console je Seznam Webmaster, který ukazuje informace o indexovanosti a problémech s webem na Seznamu.
Teď už víte, jak zjistit počet stránek, které vyhledávače umí najít. Možná s tímto výsledkem nejste spokojeni. Představíme vám způsoby, jak to zlepšit.
Rychlost a úplnost indexace webu často mohou negativně ovlivňovat tyto faktory:
- technické překážky na podstránkách webu — s jejich odhalením a úpravou vám můžeme pomoci v rámci technického SEO auditu,
- na neindexované stránky nevedou odkazy (ať interní nebo externí),
- stránky nemají informační hodnotu nebo kopírují jiný obsah — na webu vznikají duplicity, proto stránky nejsou pro vyhledávače důležité.
Pokud používáte běžný redakční nebo e‑shopový systém, obvykle se už na začátku můžete spolehnout na to, že bude řada pastí bránících indexaci vyřešena v rámci původního nastavení systému.
O přidání jednotlivých stránek webu můžete Google požádat pomocí Google Search Console. Potřebujete k tomu Google účet, se kterým máte přístup do profilu daného webu. V nástroji můžete prozkoumat URL adresu konkrétní stránky a následně požádat o indexaci.
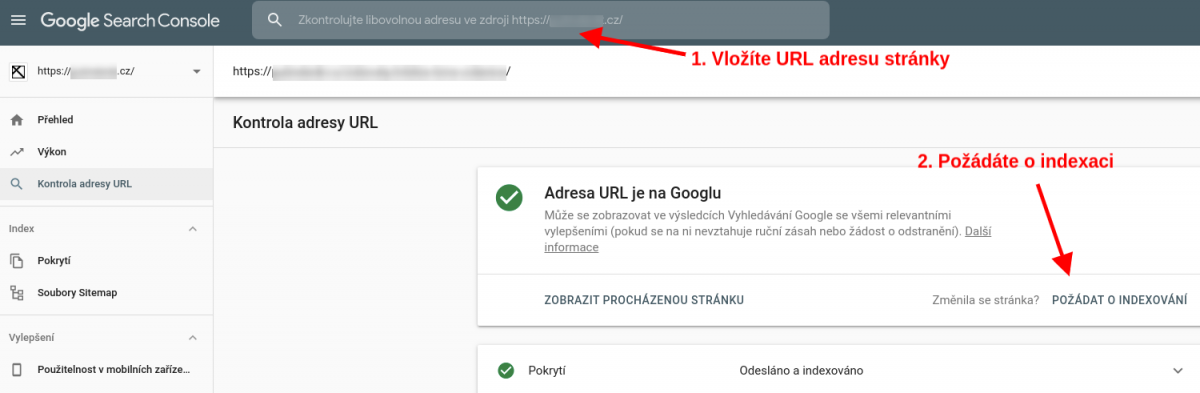
Googlu můžete obecně pomoci s rychlejší indexací a aktualizací povědomí o obsahu vašich stránek přidáním souboru sitemap do Google Search Console. Tento postup se hodí zejména v případech, kdy nemáte soubor sitemap na standardizované adrese domena.cz/sitemap.xml.
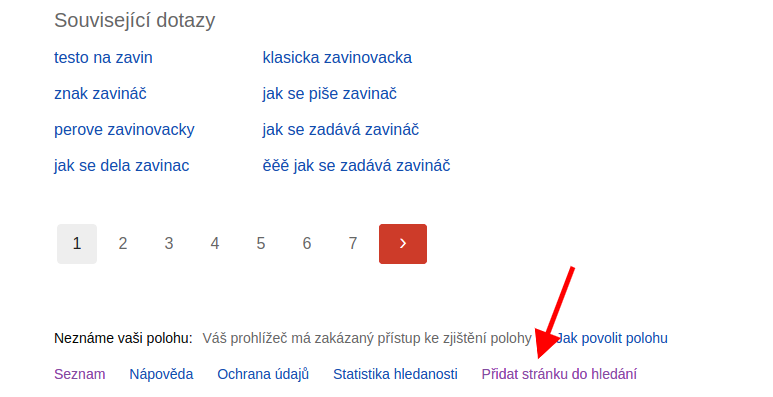
Na stránce výsledků vyhledávání Seznamu najdete v patičce několik odkazů, mezi nimi i “Přidat stránku do hledání”, případně můžete využít odkaz “seznam add url”.
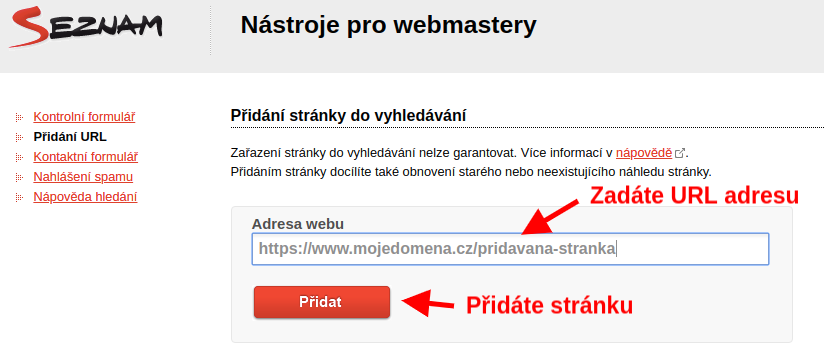
Na stránce, která se vám otevře, přidáte do pole “Adresa webu” URL adresu neindexované stránky webu, kterou chcete indexovat, a odešlete ji tlačítkem “Přidat”.
Postup můžete opakovat pro více podstránek vašeho webu. Při spuštění nového webu můžete pro začátek takto ručně přidat hlavní stránku a hlavní kategorie. Obvykle se do pár dnů objeví ve výsledcích vyhledávání a postupně se v něm začnou objevovat i méně důležité stránky webu, například konkrétní produkty.
Dosáhnout rychlejší a úplnější indexace na Seznamu jde i jednodušeji, přitom s větším efektem:
- zkuste použít aplikaci Seznam Index Checker v Mergadu, pro kterou jsme vám připravili návod,
- využijte funkci SWT reindexer v Collabimu.
Jak Collabim, tak aplikace v Mergadu fungují obdobně. Jsou napojeny na API rozhraní nástroje Seznam Webmaster. Z něj získávají informace, které stránky jsou indexované. Aplikace poté zasílají zpátky požadavky Seznam robotům na navštívení URL adres neindexovaných stránek. Takto můžete odeslat požadavek až pro 500 stránek denně.
Prodáváte stejný sortiment jako konkurence a přebíráte kompletní data o produktech z dodavatelova feedu? Pak budete mít prakticky totožný obsah produktových stránek jako konkurence.
V případě duplicitního obsahu napříč různými webovými stránkami má výhodu ten, komu vyhledávače indexovaly produktové stránky dříve.
Pokud se vám podaří od dodavatele získat produktová data nového sortimentu přednostně, publikujte je co nejdříve na webu. Máte pak větší šanci než konkurence získat návštěvnost z neplaceného vyhledávání. Vyhledávače vám stránky zaindexují a ve výsledcích budou vidět jako první v případě, že lidé použijí vyhledávací výrazy, kterým nové produktové stránky odpovídají.
Opakování na závěr
Aby vyhledávače zobrazovaly stránky webu ve výsledcích vyhledávání, musí je indexovat. Na webu se však mohou vyskytovat technické překážky, které v indexaci robotům brání. Proto je dobré udělat si o stavu webu přehled. Úroveň indexace můžete snadno zjistit pomocí volně dostupných nebo placených nástrojů. Zvýšení stavu indexace pak může i sami pomoci.
Stále si nevíte rady se zjistěním stavu nebo se vám nedaří zlepšit úroveň indexace? Můžeme vám pomoci, napište nám.
Komentáře (2)
Ahoj Michale,
o indexaci má smysl usilovat u stránek, které cílí na dotazy, které mají hledanost. Jeden z cílů SEO je vytvořit stránky, které odpovídají na co největší množství dotazů, pro které máš sortiment. Ale tyto dotazy už musí být hledané. Jinak rozdrobíš autoritu svého webu na příliš malé částečky.
1) Jsou e‑shopy, u kterých lze pokrýt vyhledávané dotazy běžnými kategoriemi. U nich dává smysl indexovat hlavně je, produkty a hlavní stránku, případně nějaký blog.
2) Jsou e‑shopy, u kterých není možné rozumně pokrýt vyhledávané dotazy pomocí běžných kategorií. V tom momentě přichází na řadu filtry, které ale musí být indexovatelné. Dokáš jimi pokrýt vyhledávací dotazy typu “kategorie + filtr” např. “dřevěné kuchyňské linky 280 cm”.
Obvykle dává smysl indexovat kategorii v kombinaci s 1 vlastností najednou. Dvoj, troj a více kombinace většinou jen vytváří obrovské množství stránek bez užitku (neodpovídají vyhledávaným dotazům).
Ani jednokombinace nemusí vždy dávat smysl. Dejme tomu, že kategorie má filtry — barva, šířka, počet polic. Při průzkumu hledaných dotazů, zjistíš, že hledané jsou jen kombinace “kategorie + šířka”. Udeláš indexovatelné jen filtry pro šířku.
Máš Martine prosím doporučení, pro jaký obsah fulltextové vyhledávače motivovat k jeho indexaci a pro jaký už nikoliv? Mířím k např. k různým katalogům zboží, e‑shopům — kdy např. použitím filtrů v kategorii může vzniknout nespočet kombinací různých výběrů. Jsou SEO specialisté, kteří o jejich indexaci usilují a jiné zase nikoliv. Máš doporučení, jak rozhodnout, který obsah ještě cíleně vyhledávačům posílat?
Děkuji.